Platform
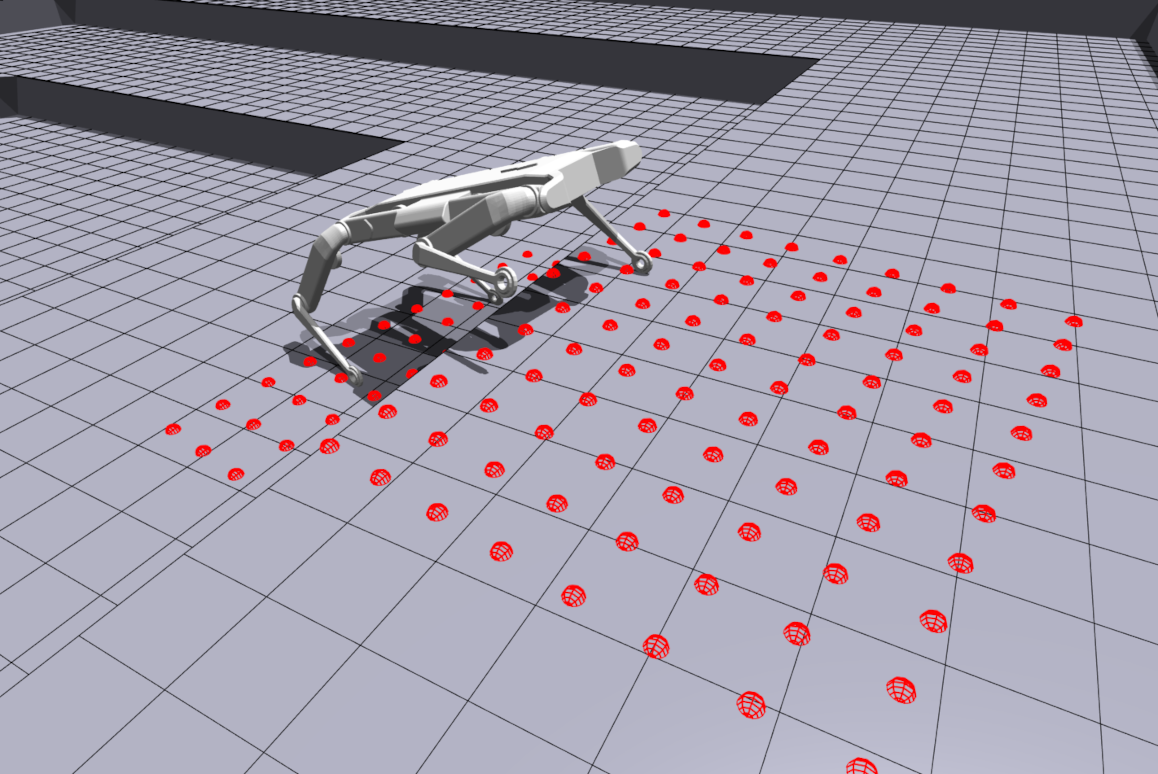
Using CaT our Solo-12 robot can walk up stairs, traverse slopes, and climb over high obstacles. This 24-cm platform is almost as high as the quadruped in its default configuration.
Deep Reinforcement Learning (RL) has demonstrated impressive results in solving complex robotic tasks such as quadruped locomotion. Yet, current solvers fail to produce efficient policies respecting hard constraints.
In this work, we advocate for integrating constraints into robot learning and present Constraints as Terminations (CaT), a novel constrained RL algorithm. Departing from classical constrained RL formulations, we reformulate constraints through stochastic terminations during policy learning: any violation of a constraint triggers a probability of terminating potential future rewards the RL agent could attain. We propose an algorithmic approach to this formulation, by minimally modifying widely used off-the-shelf RL algorithms in robot learning (such as Proximal Policy Optimization).
Our approach leads to excellent constraint adherence without introducing undue complexity and computational overhead, thus mitigating barriers to broader adoption. Through empirical evaluation on the real quadruped robot Solo crossing challenging obstacles, we demonstrate that CaT provides a compelling solution for incorporating constraints into RL frameworks.
Using CaT our Solo-12 robot can walk up stairs, traverse slopes, and climb over high obstacles. This 24-cm platform is almost as high as the quadruped in its default configuration.
CaT can enforce a wide variety of task-dependent constraints. Here, CaT limits the height of the base to learn crouching locomotion skills and pass under an obstacle.
The quadruped robot is trained with CaT in simulation using a height-map scan directly extracted from the generated terrain . The learned policy is then directly deployed on the real robot. As Solo-12 is blind and knowing the obstacle course on which the robot is placed, we use external motion capture cameras to reconstruct the height-map of its surroundings based on its position and orientation in the world.

CaT can enforce safety constraints to ensure that policies learned in simulation will transfer well and safely to the physical robot once training is complete. Here, joint torques mostly remain within the limits of ±3 Nm set during training even when climbing on a platform almost as high as the robot. Short violations can still happen in demanding situations due to the stochasticity of the policy, here during only 0.05s and up to 3.17 Nm (hightlighted in violet on the graph).
@inproceedings{chane2024cat,
title={CaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning},
author={Elliot Chane-Sane and Pierre-Alexandre Leziart and Thomas Flayols and Olivier Stasse and Philippe Sou{\`e}res and Nicolas Mansard},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year={2024}
}